| Accession: | |
|---|---|
| Functional site class: | PCNA binding PIP Box |
| Functional site description: | The PCNA binding motifs include the PIP Box, PIP degron, the APIM and the TLS motif. These motifs are found in proteins involved in DNA replication, repair, methylation and cell cycle control. |
| ELMs with same func. site: | LIG_PCNA_APIM_2 LIG_PCNA_PIPBox_1 LIG_PCNA_TLS_4 LIG_PCNA_yPIPBox_3 |
| ELM Description: | The cyclin dependent kinase (CDK) inhibitor p21 prevents cell cycle progression by blocking the activity of G1 phase CDKs. Upregulation of p21 in response to DNA damage causes cell cycle arrest until DNA is repaired, providing an essential link between genotoxic stress and cell cycle signalling [Bertolin,2015]. The metazoan PCNA binding PIP Box can be represented by the high affinity motif of p21 bound to PCNA (1AXC). The structure reveals two major binding sites formed by the smaller ‘Q pocket’ and a large hydrophobic groove on PCNA [Gulbis,1996]. The ‘Q-pocket’ accommodates the first glutamine residue in LIG_PCNA_PIPBox_1, through van der Waals contacts and two hydrogen bonds to the backbone of Ala252 and Ala208 of PCNA. While Gln provides the highest affinity, the ‘Q pocket’ also accepts hydrophobic residues such as Met in the Ribonuclease H2 subunit B protein RNH2B [2ZVK] [Bubeck,2011] which interacts with Val45, Ala208, Tyr211, and Leu251 of PCNA in a hydrophobic manner. The core of the motif is formed by hydrophobic and aromatic residues of the ligand (Met147, Phe150 and Tyr151 in p21) also termed the ‘hydrophobic plug’ (⏀xx⏀⏀). These residues adopt an extended conformation with one short 310 amphipathic helix that binds to a hydrophobic pocket on PCNA via van der Waals contacts and proline packing. The first helical turn provides an aliphatic residue, often Leucine. The second helical turn provides two hydrophobic positions that are frequently phenylalanine but almost always aromatic. Following the core PIP Box helix, there are no required amino acid residues. However, there are usually additional interactions that contribute to the binding affinity, for example beta augmentation backbone interactions [Gulbis,1996]. Many PIP Boxes have positively charged residues after the core helix [Prestel,2019] and, for the PIP Box degrons that also bind the Cdt2 ubiquitin ligase (DEG_CRL4_Cdt2_1 and DEG_CRL4_Cdt2_2), multiple positive charges are always present [Abbas,2008]. |
| Pattern: | [QM].[^FHWY][LIVM][^P][^PFWYMLIV](([FYHL][FYW])|([FYH][FYWL])).. |
| Pattern Probability: | 0.0000866 |
| Present in taxons: | cellular organisms Eukaryota |
| Interaction Domain: |
PCNA_C (PF02747)
Proliferating cell nuclear antigen, C-terminal domain
(Stochiometry: 1 : 1)
|
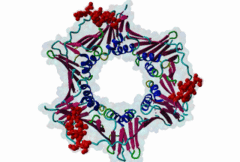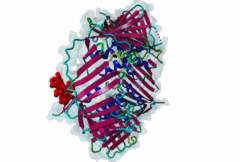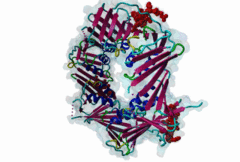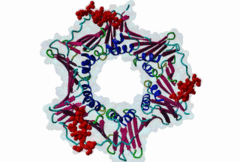
Eukaryotic genome duplication occurs during the DNA synthesis (S) phase of the cell cycle and ensures the transmission of genetic material to daughter cells. While this process occurs with remarkable fidelity, obstacles such as DNA lesions can lead to replication failure and chromosomes breaks, endangering genome integrity and cell viability [Moldovan,2007]. Several safeguard processes are integrated with DNA replication to sense DNA damage and allow the completion of replication using lower fidelity translesion (TLS) polymerases (Pol η, ι and κ) or initiate cell apoptosis when the damage can’t be bypassed. DNA synthesis occurs at the replication fork, where the Proliferating Cell Nuclear Antigen (PCNA) "sliding clamp" trimer acts as a scaffolding protein that orchestrates the assembly of replicative DNA polymerases, acts as a loading platform for replication factors, and integrates DNA damage and cell cycle signalling with DNA repair by recruiting TLS polymerases to the damage site to allow DNA synthesis across DNA lesions [Moldovan,2007]. The Rev1 polymerase acts as an additional molecular bridge between PCNA and TLS polymerases to facilitate polymerase exchange at stalled replication forks [Leung,2018]. Many proteins bind to PCNA through PCNA binding motifs, leading to their recruitment to the DNA replication fork. The LIG_PCNA_PIPBox_1, LIG_PCNA_APIM_2, LIG_PCNA_yPIPBox_3 and LIG_PCNA_TLS_4 motifs mediate an interaction with the PCNA PIP Box binding cleft. Among PCNA-binding proteins are enzymes involved in DNA replication, DNA repair and DNA methylation [Choe,2017]. PCNA acts as a scaffold for the integration of DNA replication with cell cycle and DNA damage signalling through the action of cell cycle regulators such as p21, which bind to PCNA using a PIP Box motif [Gulbis,1996]. The PCNA PIP-binding cleft also mediates binding of the related degron motifs DEG_CRL4_CDT2_1 and DEG_CRL4_CDT2_2. The variant PIP degron motif not only interacts with PCNA but also binds the CRL4-Cdt2 ubiquitin ligase through additional interactions, leading to the ubiquitination and proteasomal degradation of PIP degron-containing proteins following DNA damage or during S-phase [Abbas,2008]. The PIP Box, APIM and TLS variants target the same binding cleft in PCNA. The classical PCNA binding motif is termed the PIP Box [Warbrick,2000]. The core of the PIP Box motif forms a short 310 helix which interacts with a hydrophobic patch on the outer surface of the PCNA clamp through three conserved hydrophobic positions (⏀xx⏀⏀) flanked N-terminally by an additional residue which is often Q and binds to the conserved ‘Q pocket’ of PCNA (1U7B) [Bruning,2004]. PIP Boxes have a conserved hydrophobic core in vertebrate and fungal proteins, but the metazoan motif features aromatic residues at the last two positions, while fungal motifs show higher sequence variability leading to two motif variants (LIG_PCNA_PIPBox_1 and LIG_PCNA_yPIPBox_3). While the core hydrophobic positions (⏀xx⏀⏀) are shared between all PCNA motifs, additional binding determinants are present which tune the binding affinity. The APIM (LIG_PCNA_APIM_2) [Gilljam,2009] and TLS (LIG_PCNA_TLS_4) [Hishiki,2009] motif variants do not bind the Q-pocket. This is compensated by additional hydrophobic interactions in APIM motifs and by a negatively charged residue in TLS motifs that binds to human PCNA His 44, increasing binding affinity. Several non-canonical motifs exist that harbour substitutions at conserved sites, highlighting the plasticity of this binding cleft [Prestel,2019]. A prominent feature of most PIP Box motifs is the enrichment in positively charged residues in the motif core and flanking regions [Prestel,2019]. The range of binding affinities of PIP Box variants covers the low nanomolar (as seen in p21) to the micromolar range and can be strongly modulated by the presence of positive charges in the motif flanking regions, which can increase binding affinity by several orders of magnitude [Prestel,2019]. Considering the multiple processes orchestrated by PCNA, the affinity of each target might function in fine-tuning the different functional outputs of this replication hub. Post-translational modifications such as ubiquitylation and SUMOylation of PCNA act as switches that lead to the recruitment or inhibition of different binding partners and the activation of specific functional states [Moldovan,2007, Leung,2018]. For example, mono versus polyubiquitylation modulates the choice of the error-prone translesion synthesis (TLS) pathway versus the error-free template switching (TS) pathway [Leung,2018]. The mono ubiquitylation of PCNA at K164 in response to DNA damage allows the cooperative binding of ubiquitin binding motifs and PIP Box motifs present in TLS polymerases, enhancing their recruitment to the PCNA platform. During S phase, SUMOylated PCNA prevents unwanted homologous recombination. The anti-recombinogenic Srs2 helicase is recruited to SUMO-PCNA through its C-terminal domain, which contains a SUMO interaction motif (SIM) and a non-canonical PIP Box motif [Leung,2018]. The PIP Box is remarkable in that it is one of the few linear motifs found in all kingdoms of life: Fen1 has a C-terminal PIP Box-like motif in Eubacteria and Archaea as well as in Eukaryotes. Finally, PIP Box, APIM and TLS are part of a larger group of PIP-like motifs that include the TLS polymerase Rev1-interacting RIR motif (LIG_REV1ctd_RIR_1) and the mismatch repair Mlh1-interacting MIP motif (LIG_MLH1_MIPbox_1) [Ohashi,2009, Gueneau,2013]. Many PCNA targets harbour a combination of PIP Box and RIR or MIP motifs that cooperate in orchestrating DNA repair mechanisms at the PCNA hub, for example many TLS polymerases (Polη, ι and κ) contain both PCNA and Rev1 binding motifs that act cooperatively for recruiting these polymerases to PCNA. These helical motifs all have similar consensus sequences that prominently feature two adjacent aromatic residues. PIP-like motifs are functionally interlinked, as they all cooperate in different aspects of DNA repair signalling, and might show an unexpected degree of cross-functionality [Boehm,2016,Boehm,2016]. |
(click table headers for sorting; Notes column: =Number of Switches, =Number of Interactions)
Please cite:
ELM-the Eukaryotic Linear Motif resource-2024 update.
(PMID:37962385)
ELM data can be downloaded & distributed for non-commercial use according to the ELM Software License Agreement
ELM data can be downloaded & distributed for non-commercial use according to the ELM Software License Agreement